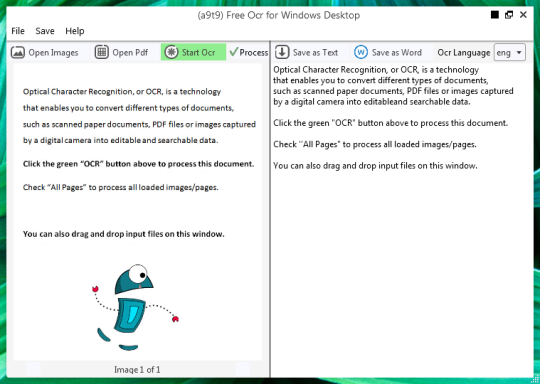
ফ্রি OCR সফটওয়্যার ইমেজ ফাইল এবং পিডিএফ আইটেম থেকে টেক্সট নিষ্কাশন. Tesseract OCR ইঞ্জিন জন্য একটি গ্রাফিকাল ইউজার ইন্টারফেস (GUI).
আবেদন, ওপেন সোর্স এবং 100% অ্যাডওয়্যারের এবং স্পাইওয়্যার বিনামূল্যে ব্যবহার করতে, আরো গুরুত্বপূর্ণ, এবং ইনস্টল করা সহজ.
আপনি একটি ইমেজ বা পিডিএফ ফাইল খুলতে পারে. সোর্স ফাইল বিষয়বস্তু বাম উইন্ডোর প্রদর্শন করা হবে. আপনি মাল্টি পৃষ্ঠা নথি খোলা যদি একাধিক পৃষ্ঠা হিসাবে আপনার দস্তাবেজ, বা, তাদের মধ্যে পরিবর্তনকালে নীচের তীর ব্যবহার করা হলে,
আপনি সবুজ, OCR বাটন ক্লিক করে আপনি OCR শুরু, এবং আপনি দ্বিতীয় ডান উইন্ডোতে ফলাফল দেখতে পাবেন. আউটপুট টেক্সট একটি টেক্সট ফাইল বা শব্দ নথি হিসাবে সংরক্ষণ করা যাবে.
দুর্ভাগ্যবশত রূপান্তর মানের এত বড় হয় না. দৃশ্য পিছনে এটা Tesseract ওপেন সোর্স OCR ইঞ্জিন ব্যবহার করে. মানের ভাষা থেকে ভাষা পরিবর্তিত হয় -. এটি আপনার প্রয়োজনের জন্য যথেষ্ট, তাই যদি এগিয়ে যান এবং পরীক্ষা
সফটওয়্যার ডেভেলপারদের এবং geeks জন্য: উইন্ডোজ ডেস্কটপ টুল জন্য বিনামূল্যে OCR মূলত Tesseract OCR ইঞ্জিন জন্য একটি গ্রাফিকাল ইউজার ইন্টারফেস সামনে শেষ (গ্রাফিক্যাল ইউজার ইন্টারফেস) হয়. পুরো সোর্স কোড (জিপিএল লাইসেন্স) পাওয়া যায়.
সফ্টওয়্যার OCR ইঞ্জিন নিম্নলিখিত OCR ভাষা সমর্থন: ইংরেজি, ফরাসি, ইতালিয়ান, জার্মান, পর্তুগিজ এবং ডাচ ব্রাজিলিয়ান, স্প্যানিশ. এটা হাঙ্গেরীয় বুলগেরিয়ান আরবি, কাটালান, চীনা (সরলীকৃত ও পরম্পরাগত), ক্রোয়েশীয়, চেক, ড্যানিশ, ডাচ, ইংরেজি, জার্মান (মান এবং ফ্রাকটুর স্ক্রিপ্ট), গ্রিক, ফিনিশ, ফরাসি, হিব্রু, হিন্দি, সনাক্ত করতে পারে সংস্করণ 3 থেকে শুরু করে, ইন্দোনেশিয়ান, ইটালিয়ান, জাপানি, কোরিয়ান, লাত্ভীয়, লিথুয়ানিয়ান, নরওয়েজিয়ান, পোলিশ, পর্তুগীজ, রোমানিয়ান, রাশিয়ান, সার্বিয়ান, স্লোভাক (মান এবং ফ্রাকটুর স্ক্রিপ্ট), স্লোভেনিয়ান, স্প্যানিশ, সুইডিশ, তাগালোগ, তামিল, থাই, তুর্কি, ইউক্রেরিয়ান এবং ভিয়েতনামি.
পাওয়া মন্তব্যসমূহ না